As it often happens, via a retweet I fell into a wonderful rabbit hole of exploring the Open Syllabus Explorer which has a wide range of tools and visualizations to explore metadata gleaned from millions of syllabi.
Open Syllabus is a non-profit research organization that collects and analyzes millions of syllabi to support novel teaching and learning applications. Open Syllabus helps instructors develop classes, libraries manage collections, and presses develop books. It supports students and lifelong learners in their exploration of topics and fields. It creates incentives for faculty to improve teaching materials and to use open licenses. It supports work on aligning higher education with job market needs and on making student mobility easier. It also challenges faculty and universities to work together to steward this important data resource.
Open Syllabus currently has a corpus of nine million English-language syllabi from 140 countries. It uses machine learning and other techniques to extract citations, dates, fields, and other metadata from these documents. The resulting data is made freely available via the Syllabus Explorer and for academic research.
The project was founded at The American Assembly, a public policy institute associated with Columbia University. It has been independent since 2019.
There is much more to read about how it works (mostly crawling university sites) what is actually harvested, how it is not sharing publicly the syllabi themselves.
It extracts the titles of all assigned texts and readings (see what is most referenced) but also refines that for commonly used OER Texts
OER Metrics tracks the adoption of openly-licensed textbooks and monographs in higher education, using licensing information from the Open Textbook Library and the Directory of Open Access Books.
Once you drill down a title, e.g. Eric Von Hippel’s Democratizing Innovation you can see it has been used in 448 syllabi, see a count by discipline of what kinds of courses it has been used it, see a map of the institutions where the book is used, what other readings are often co-assigned with it, and a link to see the title in the “co-assignment galaxy”
The galaxy is where it gets very interesting- a mapping of the relationships of the top one million referenced texts, where they are grouped by affinity of common use.
The layout approximates the structure of the citation graph formed by connecting syllabi with the books and articles that are assigned in the course
Like a world map, from far away you cannot see much detail, but the galaxy can be navigated like a digital map (zooming in, etc)
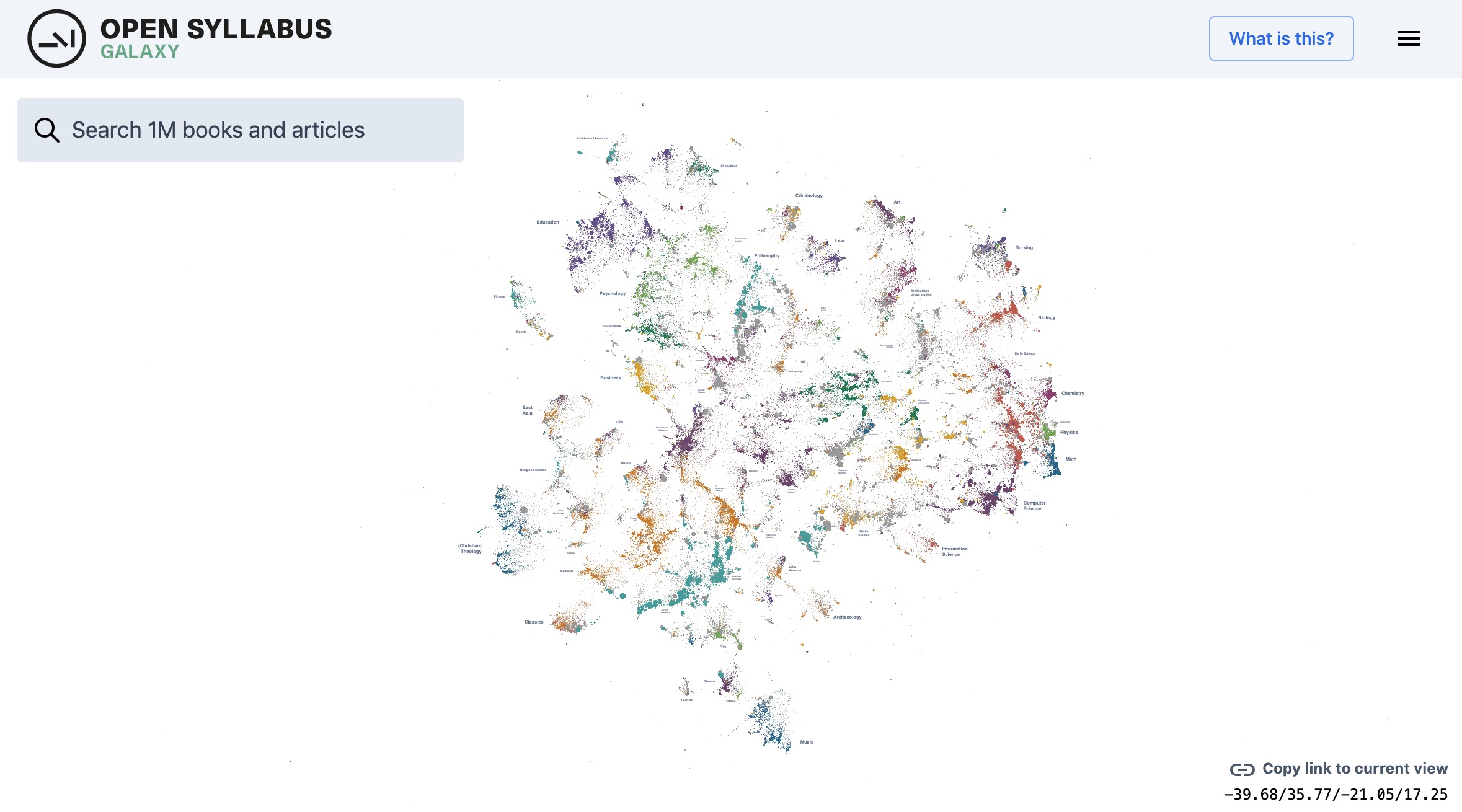
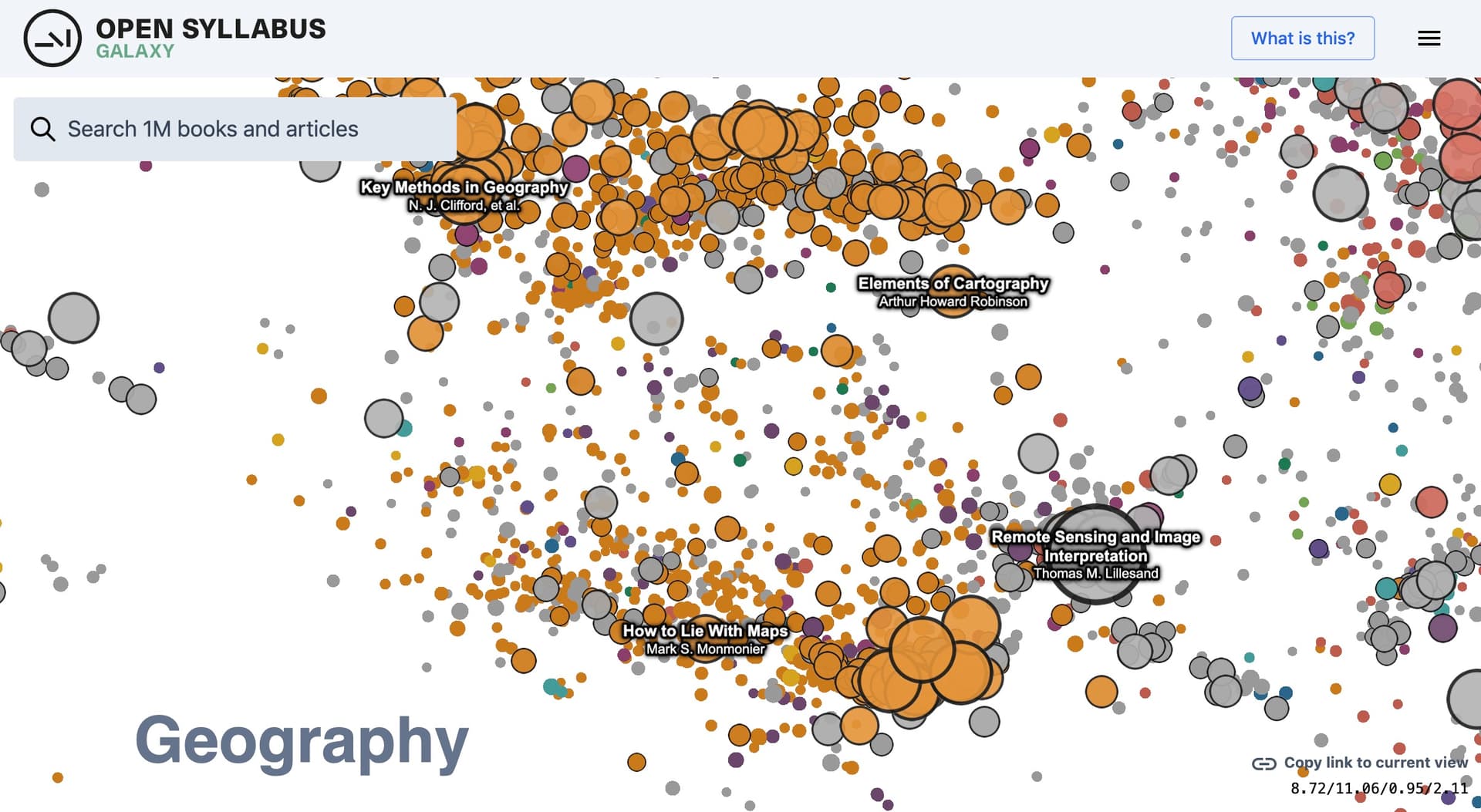
You find clusters by discipline and geographic location, here is a closer look to titles between geography and earth science (note how any view can be saved as a map-like link)
Dig around the blog and you find more interesting visualizations, like this corpus of movies and films referenced in syllabi.
While not strictly about open education or OERs, the Open Syllabus project is a stellar example of innovative use of large data sets and would seem of use to anyone doing educational research.
Also note they have a call for anyone’s shared syllabi, and when submitted you can choose to let the document be private or public. Note this part of the longer pitch:
We want the Open Syllabus Project to become a means of understanding higher education as a global project of transmitting knowledge from one generation to the next. We also want it to become a tool for democratizing and defending the integrity of that project.
as well as:
Finally, the OSP is an argument for a more open curricular culture. By showing what’s possible when curricular materials are aggregated, we hope the OSP can contribute to building it.
That seems in line with what we are about at OE Global.
I hardly saw the whole resource, but am curious what anyone else can discover here-- explore it https://opensyllabus.org/