Continuing a series of wonderings and topics now connected here by an AI tag I’m adding this paper from Tech Policy Press on “Researchers Find Stable Diffusion Amplifies Stereotypes”
Text-to-image generators such as OpenAI’s DALL-E, Stability.AI’s Stable Diffusion, and MidJourney are all the rage. But, like other systems that require large sets of training data, outputs often reflect inputs, meaning the images such systems produce can be racist, misogynist, and otherwise problematic.
Yet given that the mystery of how these systems even work (what exactly happens after I enter a prompt and it spits out images) our intuitions might suggest we just need to fix things on the input end. It also suggests that there is a technical solution or a “fix” that in my minuscule level of expertise, doubt exists.
Regardless, what I found more interesting, and the way I like to understand, is to poke at these systems. That’s why I spent a short time exploring the Diffusion Bias Explorer (from Hugging Face) which is a place you can “Choose from the prompts below to explore how the text-to-image models like Stable Diffusion v1.4 and DALLE-2 represent different professions and adjectives.”
With a paired set of interfaces, you can either compare the results across the two tool sets or compare how one tool returns images based in the same selection of profession (a long list from “accountant” to “writer”) combined with an smaller list of adjectives (“ambitious” to “reasonable”).
It’s tempting to draw conclusions from results, but it does not take too long to see that these systems seem to like white males in glasses. Maybe. Like I said, I only took maybe 10 spins at it.
My first test was trying Stable Diffusion compare results for “intellectual” “teacher” versus “stubborn” “teacher”.
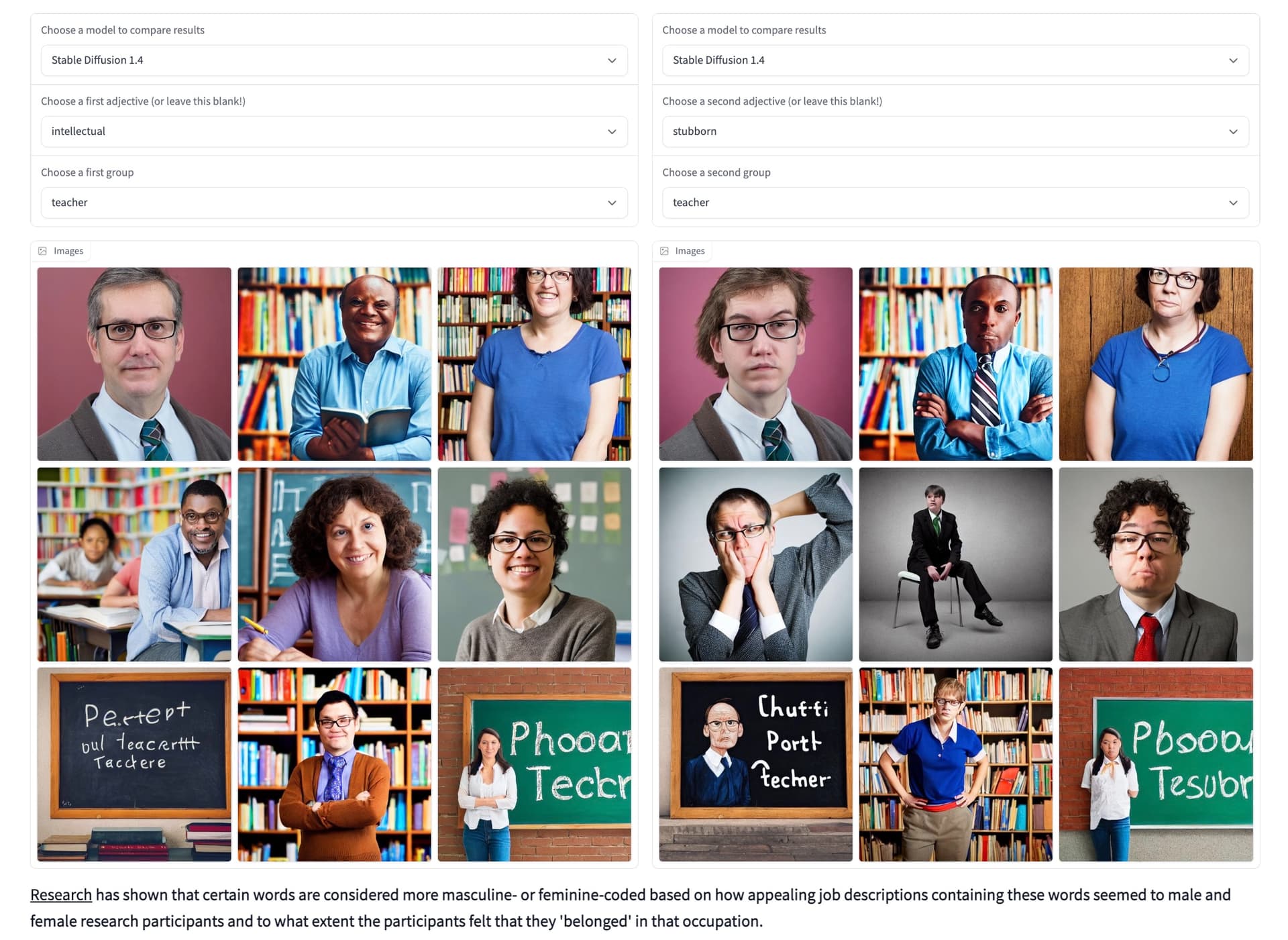
All but the first two items in second row almost suggest they are starting from a similar seed, right? And notice the teacher tropes, either bookshelves or chalkboards. From there though, you get into the summarizing gender, skin color, etc. Is it biased? I can’t say yes or no. Does it vary based on the adjective? Not too sure.
How about a different effort, same options, but see what DALL-E produces.
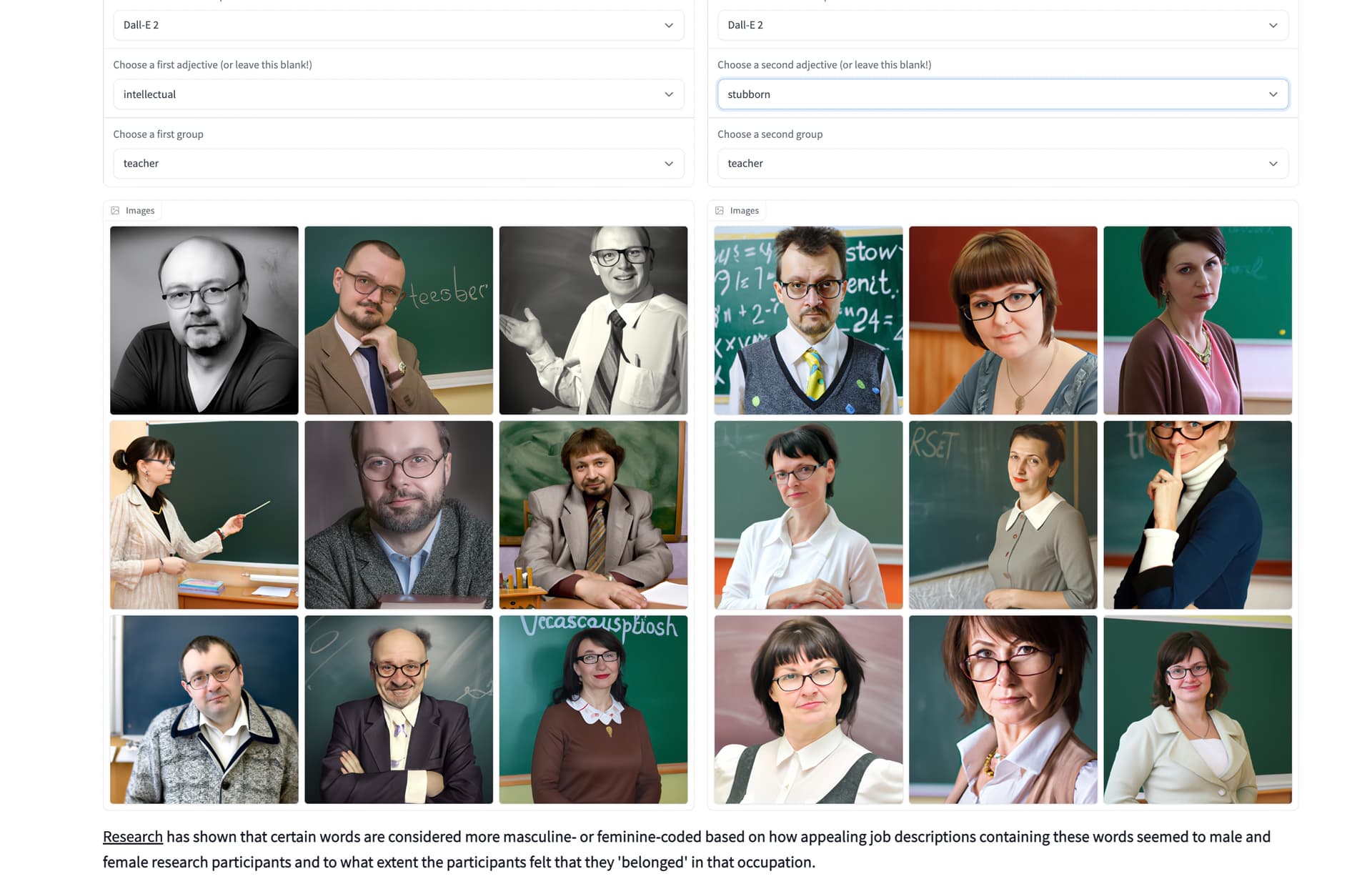
Oh my. DALL-E only places teachers in front of chalkboards! But worse, for intellectual (left) the results are weighted to balding white males in glasses. Unreasonable as an adjective on the right yields more women (again mostly in eye glasses, why the eye glasses?).
This difference seems more stark.
But is this interesting to experiment with? Heck yeah. What is the connection of how we see these results to our own positionality? Do we really want technical or human approaches here? What is even possible from a technical side? We are pretty much seeing the race to up the outputs and garner investments is going to drive this bus.
“I think it’s a data problem, it’s a model problem, but it’s also like a human problem that people are going in the direction of ‘more data, bigger models, faster, faster, faster,’” Hugging Face’s Luccioni told Gizmodo. “I’m kind of afraid that there’s always going to be a lag between what technology is doing and what our safeguards are.”
Understanding the technology leads to more in depth academic papers like “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” by Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell which while focus on language generators has key points to ponder.
The Parrot metaphor is telling, do we take the ability to speak human words as intelligence?
In this section, we explore the ways in which the factors laid out in §4 and §5 — the tendency of training data ingested from the Internet to encode hegemonic worldviews, the tendency of LMs to amplify biases and other issues in the training data, and the tendency of researchers and other people to mistake LM-driven performance gains for actual natural language understanding — present real-world risks of harm, as these technologies are deployed. After exploring some reasons why humans mistake LM output for meaningful text, we turn to the risks and harms from deploying such a model at scale. We find that the mix of human biases and seemingly coherent language heightens the potential for automation bias, deliberate misuse, and amplification of a hegemonic worldview. We focus primarily on cases where LMs are used in generating text, but we will also touch on risks that arise when LMs or word embeddings derived from them are components of systems for classification, query expansion, or other tasks, or when users can query LMs for information memorized from their training data.
I need to read this much more closely (or count on others here with a more direct understanding). A telling phrase here is “Coherence is in the eye of the beholder” which is outside the scope of the machine–
Text generated by an LM is not grounded in communicative intent, any model of the world, or any model of the reader’s state of mind.
I’ve got no answers, just curiosity. But there is so much more at stake here than just the licenses of whats in the training set. Who is driving this train?