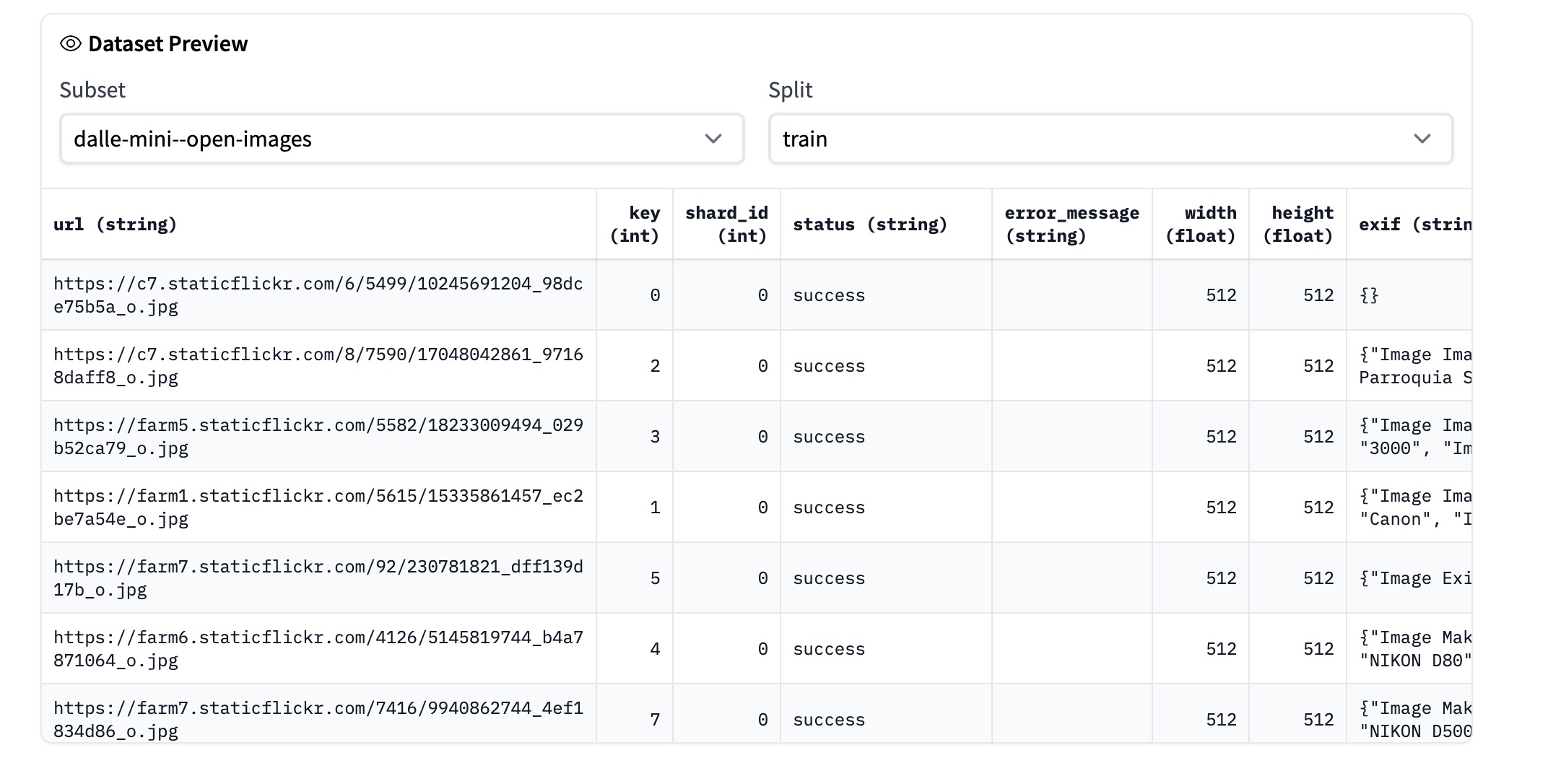
This led me to look at their “training images” (you can only see 100 rows, so there’s probably more) - they are all from flickr:
Here it is, I can now pry at some of the images used for training this machine (I still have no clue how the training happens).
Look, it’s the 4th image in that list.
I suspect though it’s more than the image that’s the training, because in the exif column comes all of the photo metadata. But I also know from my own use of the flickr API that you can also extract the photo title and caption.
But going back to that photo, it’s file name is on the end of the URL or
This is very uplifting use of facial recognition AI that no one should find a problem with.
We even learn that Rush musician Geddy Lee has been able to confirm identification of his family members (his mother is an Auschwitz survivor).
But here is the part I do not get. The interviewer asks:
We’re not all software engineers here, but can you tell us a little bit about how the software works?
Exactly! I want to hear, in plain english what AI software, algorithms do to recognize faces.
And the engineer’s response?
The software leverages AI [artificial intelligence] to help Holocaust descendants discover images of their loved ones, and identify the millions of unidentified faces in Holocaust photo and video archives.
We proactively look to identify faces using AI, and also provide a way for people to conduct their own research as well through the numberstonames.org website.
“We just wave the AI wand it it identifies faces” ???
This is what I object too- there is just this gushing over the results and we are given no understanding what goes on inside the magic AI box.
And how, exactly, is AI able to recognize faces? Well, each person’s face is broken up into numerous data points; these can be the distance between the eyes, the height of the cheekbones, the distance between the eyes and the mouth, and so on. AI facial recognition searches on those data points and tries to account for variations (for instance, distance from the camera and slight variations in the angle of the face).
However, even well-trained AI facial recognition systems don’t have real-world context and can be fooled. If you see a colleague who is wearing a face mask, sunglasses, and a baseball cap, you may still recognize them. An AI system, however, might not. It depends on level of training the neural network. Even though AI facial recognition systems are more superficially accurate, it is also easier for them to blunder under less-than-ideal conditions.
And the recommended video has experts talking about how facial recognition works, but we never see anything.
That is not how I see an explanation working for me. These are Tellplanations.
Cool! I love that you can track their data–I think Hugging Face intentionally releases this in contrast to other corporate models, right? I have been trying out the same dalle mini a bit and got a neat image for ambiguity. But I’m not sure about including these images in my OER textbook–are they public domain? Creative Commons argued something to that effect.
The Wikimedia Foundation’s 2014 refusal to remove the pictures from its Wikimedia Commons image library was based on the understanding that copyright is held by the creator, that a non-human creator (not being a legal person) cannot hold copyright, and that the images are thus in the public domain.
…
In December 2014, the United States Copyright Office stated that works created by a non-human, such as a photograph taken by a monkey, are not copyrightable
So until the claims of sentience can be established (likely not) would not images generated by AI be considered the same as ones made by a monkey?
This might end up being more a stream of finding-ness act, that maybe an algorithm can do better than me? My favorite discoveries come from places maybe I was not looking at them.
Like email.
I subscribe to Seb Chan’s Fresh and New newsletter - Seb is a powerful innovator in the museum / museum tech space, and I was fortunate to spend a little bit of time with he and his ACMI team n 2018.
Anyhow, his current Fresh and New Generative things and choosing the right words included some examples and probing thoughts on the AI image generating fad. And I really like his description of all these DALL-E sets as “promptism”
My social media feeds overflowed with DALL-E and Midjourney ‘promptism’ visuals. The coining of ‘promptism’ by others nicely deflects attention from the underlying technologies to the craft of finding the right language (the prompt) to ‘talk to the machine’. Its a bit like those people who seem to have a magical ability to craft ‘the perfect Google search query’ but aren’t trained librarians and have really just have done a bit of SEO work in their past.
More than that, and why I respect Seb, is not just talking about AI but experimenting, and developed an image generator based on metadata from his museum’s collection.
You can find examples of what their AI generated:
I have to say it is somewhat interesting that it came up with anything close to the prompt, but ???
I also gleaned from here a very good explainer video on how this generating images from text was started (32 pixel green school buses!)
An in the “to dabbe and learn more department” would be sinking my curiosity unto the Jupyter Notebooks on Google Colab (example).
Yikes, here it is the mid-point of July, meaning the mid-point of whatever season you are in, and I’ve not really progressed too much on actual AI tinkering. Just keep tracking curious, interesting stuff others are doing.
But hey, no one is grading here (and also, no one really joined in to the idea of the open pedagogy adventuring).
I thank my colleague and better long time friend Bryan Alexander for sharing the item below. For someone as prolific as he is blogging and in social media, he often sends me interesting stuff as a personal email. Just to let anyone know that a good friend is better than any algorithm.
Bryan shared author Janelle Shane’s post on “The Kitten Effect”
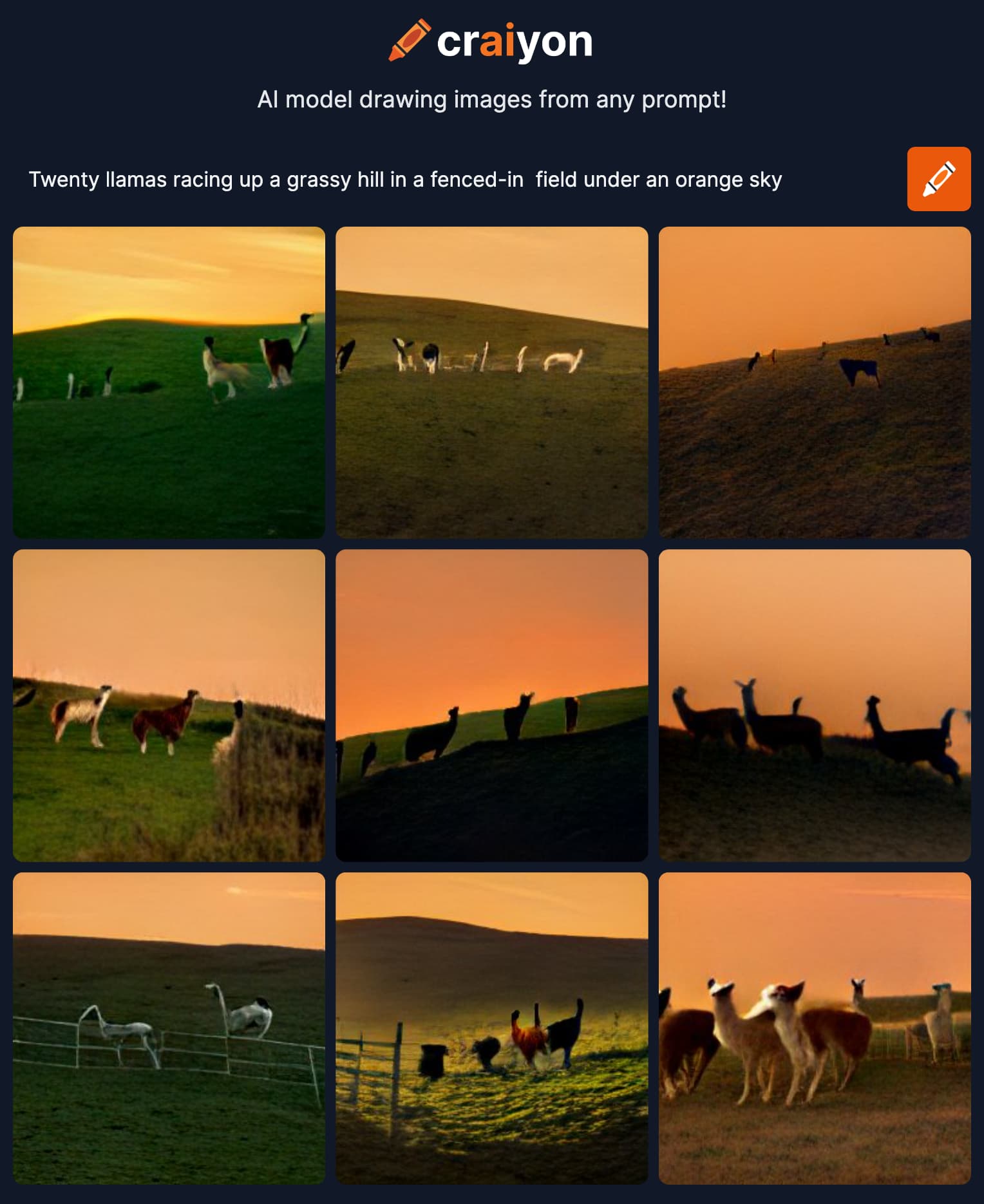
Janelle describes and shows examples that as realistic as the Dall-E 2 can be for generating images of single kittens (and dogs) (and candy), when you ask it to do larger numbers of them, or even smaller sized images, he quality really breaks down.
I don’t know for sure what to make of this, but it’s interesting.
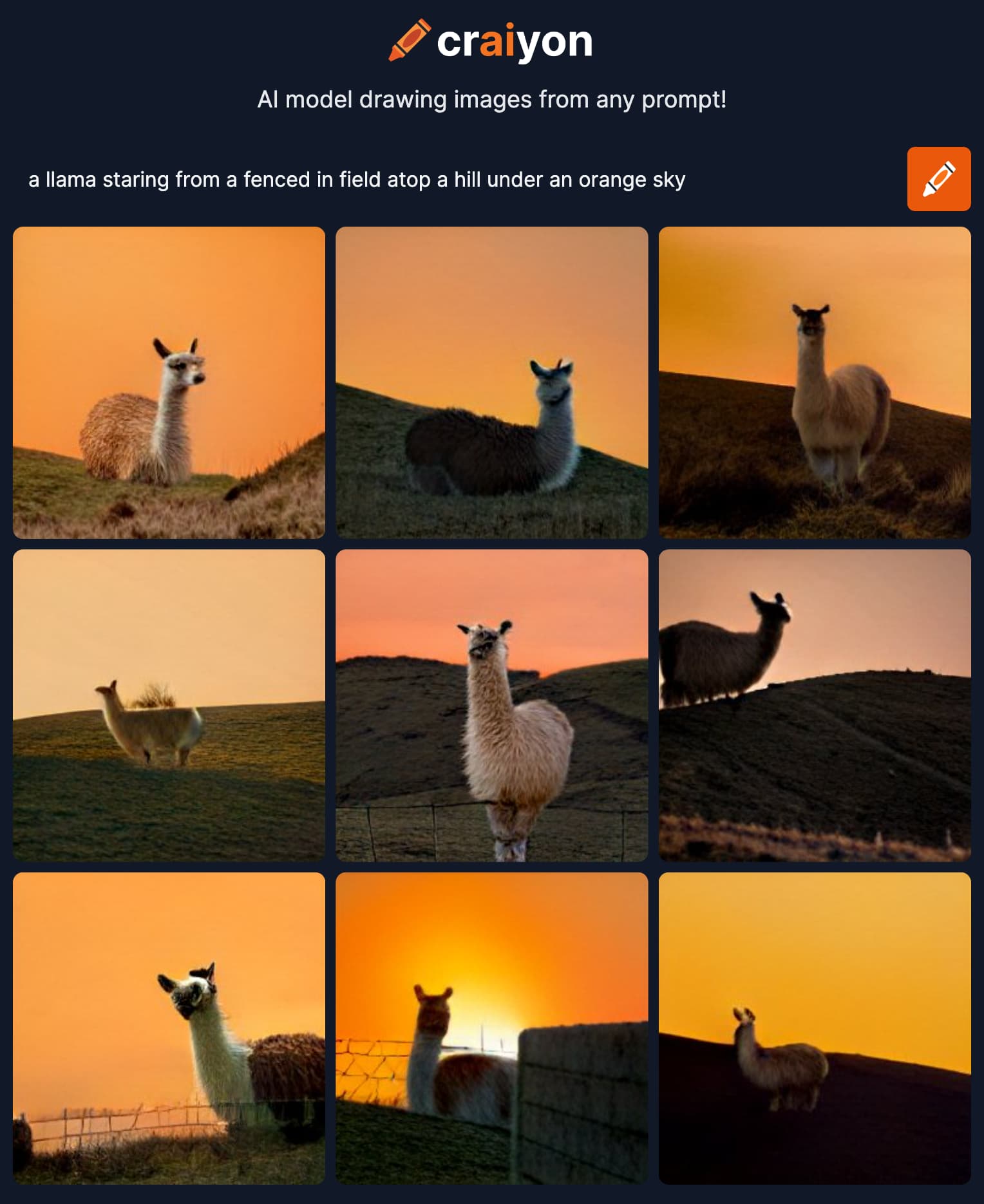
The Llama Effect?
Can I replicate this? Does the Kitten Effect apply to llamas? I choose because where I lived 2 years ago, we could walk up the lane and see 1-3 of them stare at us from behind a fence:
And I find it hard to resist a site and a book about AI Weirdness:
AI is everywhere. It powers the autocorrect function of your iPhone, helps Google Translate understand the complexity of language, and interprets your behavior to decide which of your friends’ Facebook posts you most want to see. In the coming years, it’ll perform medical diagnoses and drive your car–and maybe even help our authors write the first lines of their novels. But how does it actually work?
Janelle Shane, a scientist and engineer, has written for the New York Times, Slate, and the New Yorker. Through her hilarious experiments, real-world examples, and illuminating cartoons, she explains how AI understands our world, and what it gets wrong. More than just a working knowledge of AI, she hands readers the tools to be skeptical about claims of a smarter future.
A comprehensive study of the cutting-edge technology that will soon power our world, YOU LOOK LIKE A THING AND I LOVE YOU is an accessible, hilarious exploration of the future of technology and society. It’s ASTROPHYSICS FOR PEOPLE IN A HURRY meets THING EXPLAINER: An approachable guide to a fascinating scientific topic, presented with clarity, levity, and brevity by an expert in the field with a powerful and growing platform.
I admit my ambitions here have exceeded my capacity/time to dive much into AI, but I am still tracking things, filing away in my own cortext for where maybe they might seed future associative trails.
Here, from one of my favorite writers, Clive Thompson is the idea of “Moravec’s Paradox”
Hans Moravec is a computer scientist and roboticist who, back in the 80s, noticed something interesting about the development of artificial intelligence and robotics. Back then, the creators of AI were having some reasonable success getting computers to do “mental” work, like playing chess or checkers. But they frequently had a rough time getting robots to do physical tasks that required even the slightest bit of delicacy.
It was kind of the opposite of what many futurists and AI thinkers had long assumed about AI and robotics. They’d figured the hard stuff would be getting computers to do cerebral work — and the easy stuff would be navigating the world and manipulating objects. After all, think about a three year old kid: They can easily navigate a cluttered room and pick up a paperback, right? But they sure can’t play chess. So chess must be “hard”, and picking up a paperback “easy”.
Except in the real world of robotics and AI, inventors were discovering exactly the opposite. So Moravec realized we had a paradox of inverted expectations. Computer scientists were failing to understand what was actually hard and what was actually easy.
But in another important way, chess is really simple. It has only a few rules, and these rules operate in a completely closed system. Chess doesn’t even require any memory: Each time you look at the board, you don’t have to assess what happened in the past — you just plan for the future.
Thompson’s Phrasing of Moravec’s Paradox
This is why I enjoy this writer!
What I love about Moravec’s Paradox is that you can apply it — a kind of metaphoric version of it, anyway — outside of the sphere of AI and robotics.
To wit: In many situations in life, we often mistake the hard stuff for the easy stuff, and the easy stuff for the hard stuff.
I came across a new AI thing to tinker with via PetaPixel
This tool supposedly can improve the quality of old photos. I gave it a try with my own family photos and riffed a bit on the allure of these acts of “promptism”
Blind face restoration usually relies on facial priors, such as facial geometry prior or reference prior, to restore realistic and faithful details. However, very low-quality inputs cannot offer accurate geometric prior while highquality references are inaccessible, limiting the applicability in real-world scenarios. In this work, we propose GFP-GAN that leverages rich and diverse priors encapsulated in a pretrained face GAN for blind face restoration. This Generative Facial Prior (GFP) is incorporated into the face restoration process via spatial feature transform layers, which allow our method to achieve a good balance of realness and fidelity. Thanks to the powerful generative facial prior and delicate designs, our GFP-GAN could jointly restore facial details and enhance colors with just a single forward pass, while GAN inversion methods require image-specific optimization at inference. Extensive experiments show that our method achieves superior performance to prior art on both synthetic and real-world datasets.
I’m glad a few people still read blogs and leave comments, hence I found out from a colleague Brian Bennett this story-- here the DALL-E mini generators do work well making abstract images to accompany blog posts about highly technical topics
Might stock image sites be trembling? Regardless, the article does include some good suggestions for prompts that I may have to take for a spin.
Just to show I can improve my own promptism, I again tried one. Seeing our cat sprawled out in front of a deck of cards, I took 2 Kings out as a set for an image I might call “Poker With Charlie”:
Can AI do this? I try Black and white cat laying in front of a deck of cards with 2 kings showing with dismal results. Most of the cats are distorted and not nearly as cute as Charlie, and the cards look like gibberish.
More in the "My AI Prompts Are Not as Good as Yours Department… I got an email update for a new post at AI Weirdness
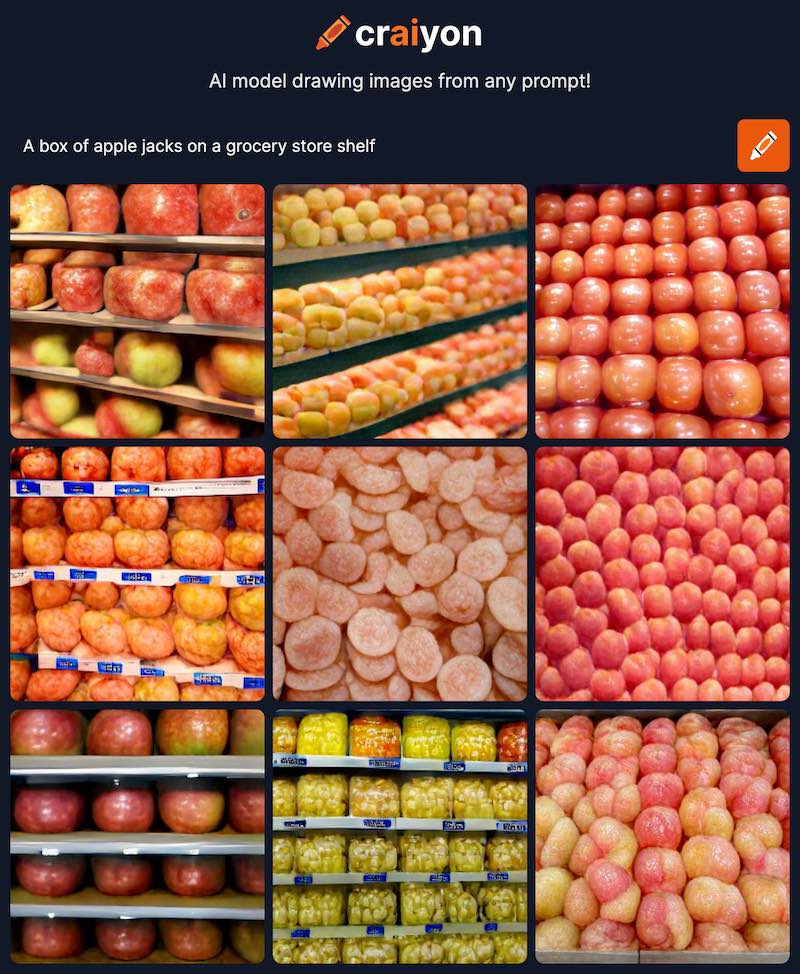
This was hard to resist as I have been a life-long fan of cereal, something which I can still use for any meal. I went to craiyon and tried a variant of the prompt the author used, mine was:
A box of apple jacks on a grocery store shelf
But all I got was mostly pictures of apples on a shelf, not my classic cereal, I was 0 for 9 in getting a box of cereal
Call me unimpressed, or maybe I should be impressed that it generated at least something I can recognized as a grocery store shelf with colors akin to Apple Jacks (well it ought to me mostly green, not reds).
Even more specificity “One single box of apple jacks cereal on a grocery store shelf” did not help, I will spare another upload, but I only got a closer up view of cereal and 2 blurred shelfs full of boxes.
I would guess that the author of an AI book has access to a better tool than the public, she mentions using DALL-E 2 which I went and signed up for the wait list (again, I did sign up in April).
While I wait my 2 minutes while craiyon chews on my prompt “A long queue of people waiting to get inside the AI palace” I anticipate more palace than – well, actually this is maybe the best I have done!
After seeing more AI promptist imagery by colleagues in Instagram and elsewhere, my realization is that judging capability as I have done based on the DALL-E mini powered craiyon is limited- more stunning images are posted using DALL•E 2 and Midjourney.
It’s fast moving, and I’m not sure I need to be trying to catch up (I applied for DALL•E 2 in April, still wait-listed).
Midjourney is interesting in that you interact via the software in the social media discord space (How to Geek as a good intro). Also for noting here, The Register’s interview with founder David Holz indicates the latest version does build upon feedback from this community, which is not built into the other apps were we individually toss prompts into a box.
The social aspect of Midjourney recently began enhancing image quality. Holz said company engineers recently introduced version three of its software, which for the first time incorporated a feedback loop based on user activity and response.
“If you look at the v3 stuff, there’s this huge improvement,” he said. “It’s mind-bogglingly better and we didn’t actually put any more art into it. We just took the data about what images the users liked, and how they were using it. And that actually made it better.”
Also of interest, curiosity-- Prompt Press that seems the generate stories that look like news using AI for imagery and text based on current headlines (?).
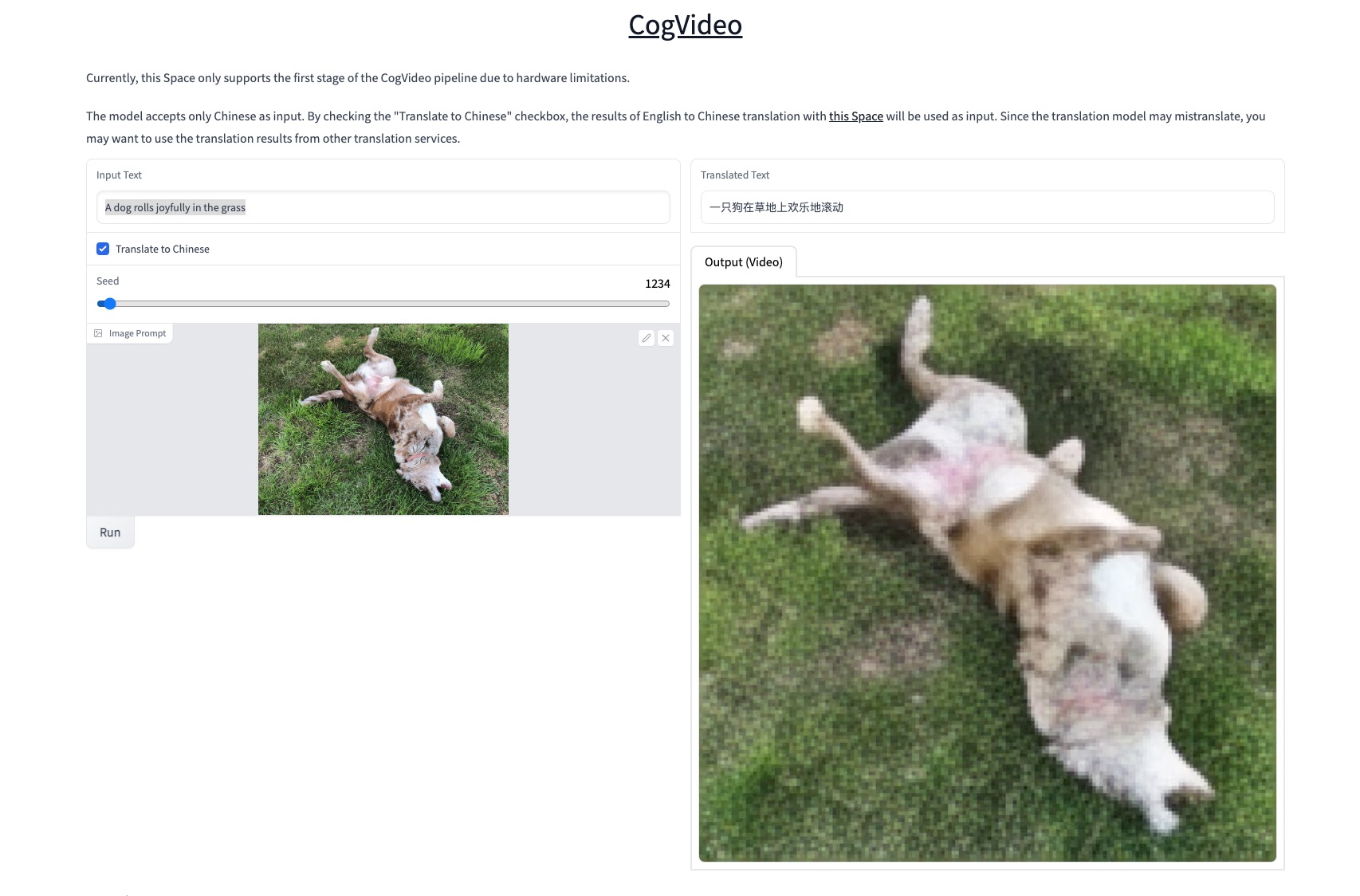
Speaking of fast moving, or just moving, gaze over the generated images of animals done in various painting styles to what might happen as video is generated by AI via something called CogVideo (no relation!). I gave it a weak try through an interface provided at Hugging Face that “only supports the first stage of the CogVideo pipeline due to hardware limitations”.
This hopefully makes one start to wonder/worry about the copyright/reuse implications here. I lost track of a really good article that dug into this, but it bends a lot of the questions of originality and remix, plus even more about the implications of the rights for the images that AI gets trained on.
And it’s going to stretch some legal precedents by pushing what non-human authorship (the usually grounds for rejecting copyright claims).
The question is what will we do, hopefully for good (?) with this capability? I am a bit weary of the shared “look what I made” (by typing into a box!). Back to the interview with Midjourney’s David Holz – it’s not art (is it creative?)
“The majority of people are just having fun,” said Holz. “I think that’s the biggest thing because it’s not actually about art, it’s about imagination.”
and
Holz said a lot of graphic artists use Midjourney as part of their concept development workflow. They generate a few variations on an idea and present it to clients to see which direction they should pursue.
“The professionals are using it to supercharge their creative or communication process,” Holz explained. “And then a lot of people were just playing with it.”
Cleaning out my fleet of open browser tabs, I found the reference I wanted to post on the issues of copyright and AI – it was a twitter thread (which is poor place IMHO to publish stuff, it just runs over the edge of now and disappears)
This might be one of the most useful twitter threads I’ve seen in a while, plucking the relevant ones-- what happens when because of it’s “training” material that AI can generate imagery that closely approximates copyrighted works?
Then the question of it being legal for AI training data to include copyrighted works (the author says “yes”).
This thread goes deep and is absolutely worth digging into.
Buried in there is an amazing set of AI tools and resources, much of it technical, but scroll to the bottom for “Cool Apps - No Code AI Art tools” e.g. stuff to play with
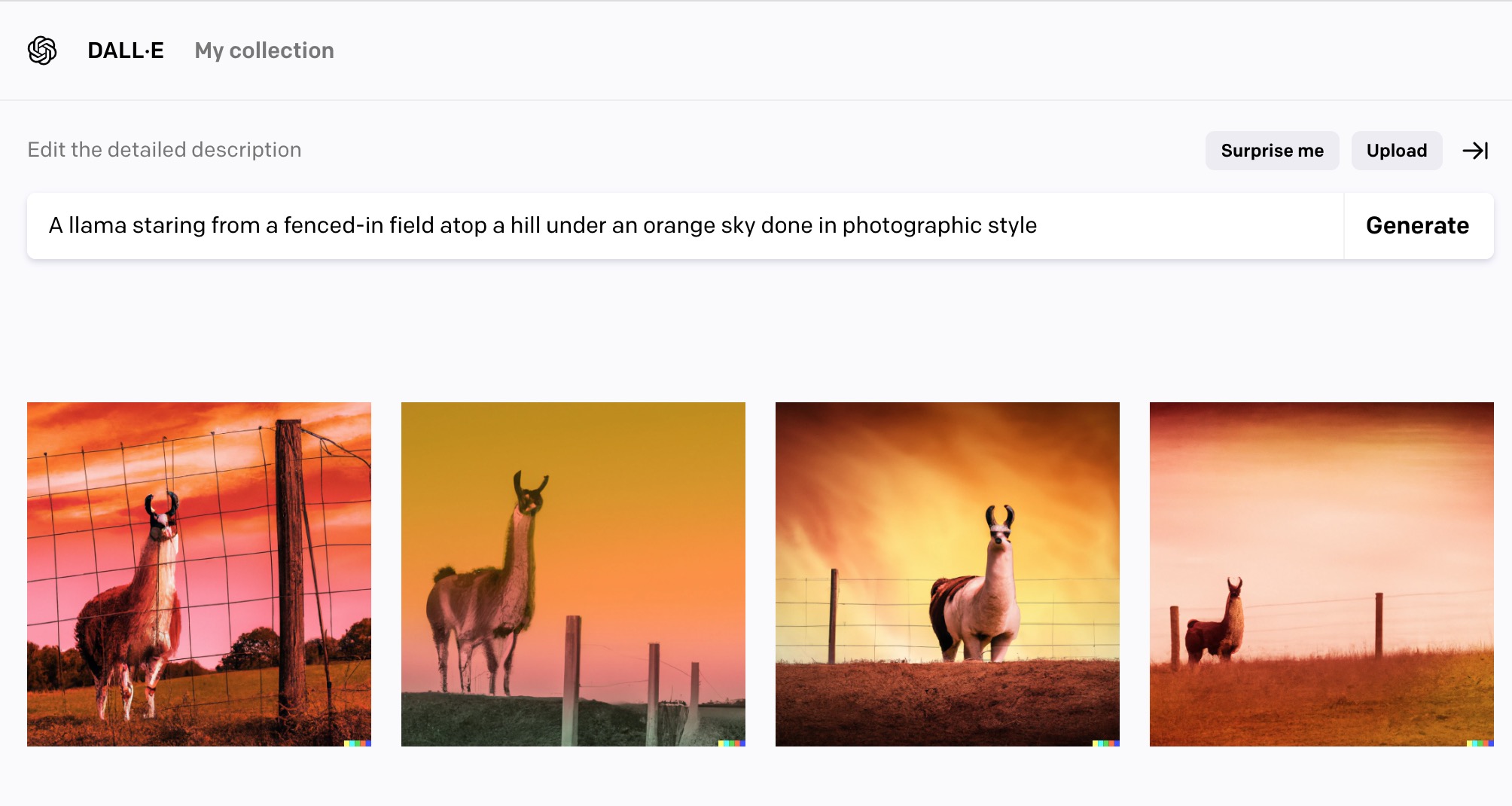
I’m in the DALL•E club, my invite came through. What shall I do with my 50 credits? For a first jaunt, I used the same llama in a field prompt I tried earlier with craiyon, just adding to the end a reference to photographic style.
A llama staring from a fenced-in field atop a hill under an orange sky done in photographic style
The images generated are much more realistic in rendering and composition than the previous attempt. Fences are more detailed, and the skies are more interesting than just “orange”
All very interesting, but to come back away from the “wow” (if that) is what can we do with this capability? Or what do we forecast as it gets even better? Might it generate something indistinguishable from a photo?
I tried to make a case or a speculation about the value of creation by tossing prompts, and here I am, like others engaged in promptism.
Okay, I am working on a new blog series for OEGlobal, where I hope to virtually travel to our members web sites and look for some interesting open education bits to share. I thought about the metaphor of traveling with a suitcase, and since I always use a dog avatar, I prompted to DALL•E
An abstract surrealistic painting of a dog sitting next to a suitcase on a wharf next to a steamship
I did ask for surrealistic, but wow, these are images I could not easily make, nor likely find.
It’s an interesting and relevant question, because the graphics that are produced are at a stage where I would want to use them, and they fit neatly what you would use for album covers or similar artworks. In other words, they have “value”. One example for my professional use would be to have an AI create visuals to use in my presentations.
Here’s a concrete example of graphics that approach being seen as “valuable” (to Dungeons & Dragons players): Dungeons & DALL·E [pack 1]
Still it’s all so new that the old ways of giving attribution are lacking. The Smithsonian article you shared (thanks) and the Creative Commons stance in 2020 make the case that AI generated images cannot be copyrighted.
Fine.
But what does that mean for reuse? Attribution? It’s all muddy.
I am guessing we are just at the veritable iceberg tip of what AI generated media will become, especially with this announcement and a few examples from DALL•E new option for “Outpainting”
The DALL·E editor interface helps you edit images through inpainting and outpainting, giving you more control over your creative vision.
So it means you can set your AI generated creatures, objects, people into scenes and backgrounds, and seems to be taking the whole realm of what used to be described as “photoshopping” to generate images, that well, might bend what we know and think of the world.
Okay, maybe that is dramatic. I was hoping to try it out since I have access now, but yes, “come back when the server is less busy” I am seeing.
On a related topic of "where the *&^$ is all this going, see the co-founder of the popular photography site fstoppers suggest big changes in the world of photography
or if you prefer listen to Lee Morris make his case.
Now his concern seems to be what does the evolution of mobile phone photography, easy to use effects and editing tools, will challenge the need for professional photographers who get paid a lot for their work.
Yes, that looks like it’s happening, but I am more interested in what it means for the nature of media creation, how we use it, reuse it, when high quality images can be easily created. Are professional photographers replaced by professional prompt writers?
Peek at PromptBase a marketplace for buying and selling AI prompts! I don’t think pro photographers see their future there (nor me).
What does this mean for educators? Can these types of media be “owned”, licensed, reshare? What are the rules of remix here?
More semi-random notes here. I asked via twitter my photography guru Jonathan Worth (he taught the open #phonar course at Coventry U back in the day) about the FStoppers piece above.
You may use the Site or the Images for academic or research purposes or for educating or entertaining on various social media platforms.
…
…
Free commercial use requires you to attribute images to Craiyon.
It has a quasi ND phrasing:
Except as otherwise provided herein, you may not modify, publish, transmit, reverse engineer, participate in the transfer or sale, create derivative works, or in any way exploit any of the content, in whole or in part, found on the Site.
as well as a statement of ownership:
You agree that you do not acquire any ownership rights in the Images, though you are permitted to use them in accordance with these Terms.
Still, I am looking to figure out how one ought to attribute such images.
As this topic was set up first under “Summer Open Pedagogy Adventure” it ought to wrap up, but it’s only the end of summer in one hemisphere, so I can change that rule.
Seeing the reactions to AI generated Art, like prize winning one, seems to say more about humans than machines. That someone created a printed ar work that one a prize show people pushing boundaries, but also others overreacting by harassing him.
Is AI the problem?
I am hardly the first to ponder his, but imagined how the invention of the camera must have been seen by the established artists of the late 19th century. I found many “takes” on this that get to a point that the disruptive nature of a new technology faded as what could be produced evolved into an art form.
This essay was a valuable read, with the opening question
First, many people believed that photography could not be art, because it was made by a machine rather than by human creativity.
with the requisite reference to artist reaction"From today, painting is dead!"
I will leave it to the art historians to explain the impact pf the camera on the world of painting, pushing realists to change, adapt, or just keep trying what they do.
Here Hertzmann gets to the answers:
This story provides several lessons that are directly relevant to AI as an artistic tool.
When the camera was first invented, it looked like a machine that automated the creation of art. No skill was required. Many artists feared and disparaged it. They predicted that it was going to destroy high-quality art and put the best artists out of work.
The development of computer graphics and potential for animation was seen as a threat too, but later a gain for the art/craft of animation. Art changes.
I believe that the same pattern is repeating itself with the new artistic AI tools. Naive spectators, who do not understand current AI technology or art (or both), worry that AI will make artists obsolete. Don’t believe the hype. In fact, these new tools open enormous creative opportunities for art and culture; they do not replace artists but, instead, empower them.
I see much to read in part 2!
And for the random bots that click here and maybe some lost human, what happens when we take “art” out of the questions and consider “education”??