Yesterday I shared one of my favorite flickr tricks, how to get a flickr photo page URL just from a downloaded file name.
There is a reason.
Here is one of those now all the places DALLE-mini image generators - Craiyon (clever? did an AI make up this name?) which offers “AI model drawing images from any prompt!”
Code is available for a whole bunch of things I want to look into (and do not understand now) about building one’s own. It looks like the model? or maybe the engine? is running on Hugging Face
This led me to look at their “training images” (you can only see 100 rows, so there’s probably more) - they are all from flickr:
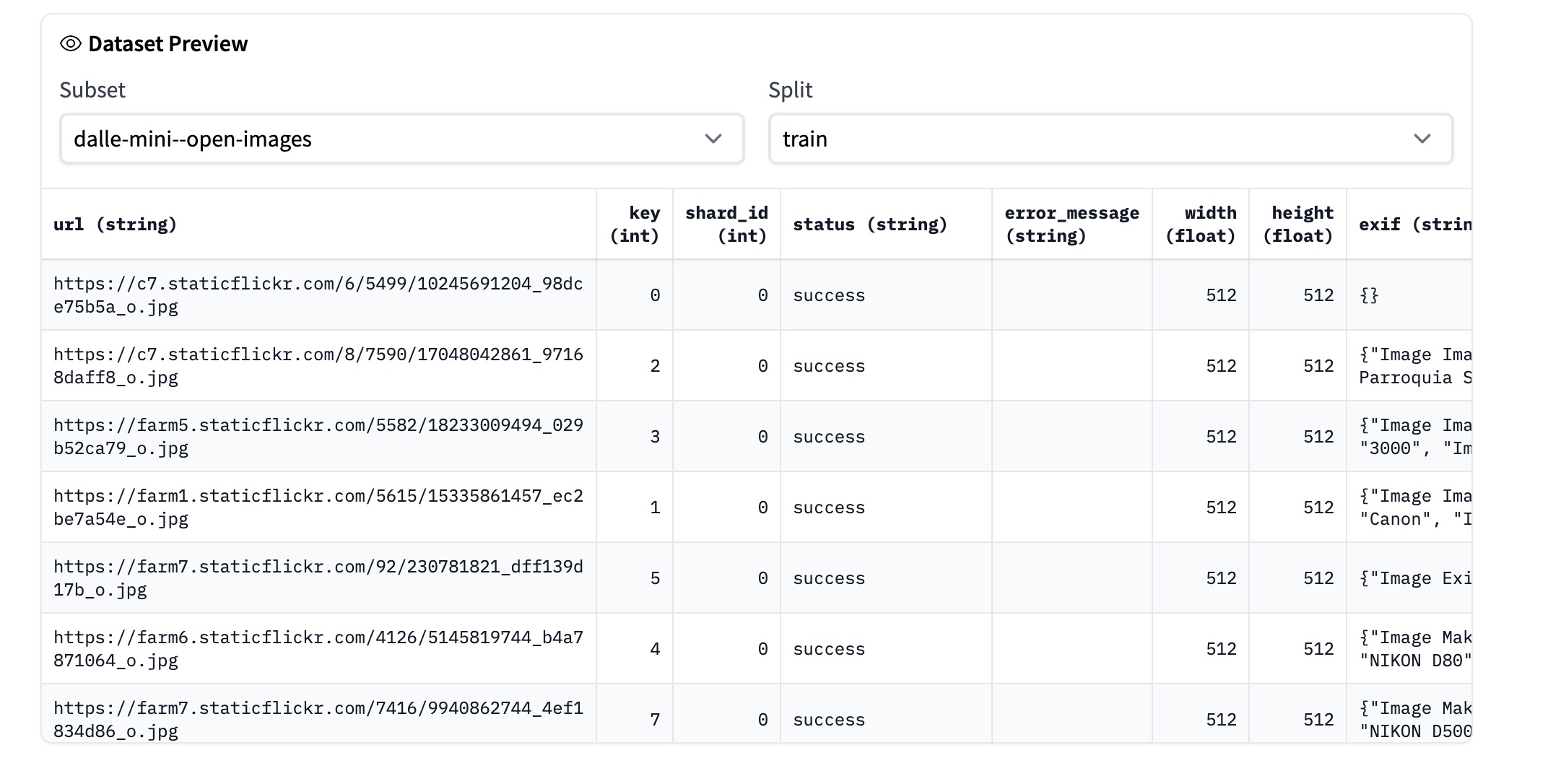
Here it is, I can now pry at some of the images used for training this machine (I still have no clue how the training happens).
Look, it’s the 4th image in that list.

I suspect though it’s more than the image that’s the training, because in the exif column comes all of the photo metadata. But I also know from my own use of the flickr API that you can also extract the photo title and caption.
But going back to that photo, it’s file name is on the end of the URL or
https://farm1.staticflickr.com/5615/15335861457_ec2be7a54e_o.jpg
which means the flickr ID 15335861457 can be used to find the original flickr page this image was taken…er borrowed from
https://www.flickr.com/photo.gne?id=15335861457
and voila, it is Downtown Detroit flickr photo by danxoneil shared under a Creative Commons (BY) license
I may not be understanding image generating AI but I am popping the hood of the car and poking around the motor.